


Reading the F-Tea-C Leaves
Assessing the the FTC's role in AI Regulation


The FTC’s Vision for AI Regulation
After a winter flurry of AI innovation, spring has brought the first regulatory shoots. Unquestionably, Washington is abuzz about AI and there is widespread hunger for action, and perhaps regulation. In the last few weeks, a sequence of releases, announcements, and guidance documents from across the federal government signal something is coming, and regulatory plans are actively underway.
While there are many agency actions worth discussing, the most significant messaging is coming from the Federal Trade Commission (FTC). While we don’t yet have any regulatory text or announced enforcement actions, we do have both clues and a rough roadmap. Let’s dive into what has been said, what we can predict, and whether it’s appropriate.
Naturally, with regulatory information moving at light speed, most of this is subject to change as information emerging.
The FTC in Charge
I’ll start with a bit of speculation. Since the new year, the FTC has released several statements and guiding documents, signaling an early interest in artificial intelligence regulation. While the FTC is an independent agency and what they say doesn’t reflect broader priorities, recent evidence may suggest these releases were the iceberg tip of a broader administration strategy to position the FTC at the center of AI policy.
On April 25th the FTC, alongside the CFPB, EEOC, and DOJ released a joint statement asserting their commitment to “to enforce their respective laws and regulations to promote responsible innovation in automated systems.” While the document provided few details about what this might mean, two things stand out. First, -the Department of Justice’s participation. As an executive agency, the DOJ represents the administration suggesting that while an independent agency, the FTC’s actions aren’t independent of a broader effort. They are in active coordination with the administration and likely have Biden’s blessing. Second, the messaging around the joint statement has been largely led by the FTC and its chairwoman, Lina Khan. This potentially hints that the FTC and Khan are being positioned to spearhead the coming AI regulatory effort.
Last week, further announcements reinforced this view. On May 3rd, Chair Khan released an Op-ed outlining the FTC’s AI regulatory plan; the next day the White House announced several new responsible AI initiatives. These back-to-back, coordinated releases further suggest that the White House is working with, and giving the green light to, the FTC. These documents also reveal a potential division of responsibility. Lina Khan’s statement is largely regulatory - focused on direct action to correct perceived market failures, AI-enabled discrimination, and fraud. Meanwhile the White House’s announcements target broader strategy; focus is placed on new R&D investments, administration-industry coordination, and executive-wide rules on the use of AI in government.
A possible read: a FTC-led consortium is going to set the rules of the regulatory road, while the White House steers the strategic ship.
What might FTC leadership look like?
If the FTC is to lead the AI regulatory effort, what might that leadership spearhead? For answers, we can look to Lina Khan’s recent op-ed which largely lays out an action plan for forthcoming AI regulation. In the document she targets several concerns and regulatory targets, some more substantiated than others. For the sake of brevity, I’ll focus on the two I find the most interesting, and concerning, and recommend potential changes to the agencies apparent strategy.
Market Structure
Chair Khan starts the piece by highlighting potential action to avert market consolidation and corporate entrenchment. Her market structure emphasis comes as no surprise. Chair Khan rose to prominence on calls to curtail perceived tech monopolization and digital platform gatekeeping. In her writing, she suggests her big tech antitrust efforts should also extend to AI to preemptively avert downstream anti-competitive behavior. Both this regulatory drive and her concerns, however, are misguided and misplaced.
First, her op-ed and the FTC’s other releases incorrectly treat AI as a single, consolidated industrial category. Today, AI is used in banking, hospitals, academia, media, and many, many other industries. Its applications are likewise incredibly diverse. Driverless cars and image generators may both be AI systems but represent radically different uses cases and industries; each deserves a bespoke treatment. With such diversity, a single ‘AI industrial concentration’ conversation just doesn’t make sense.
That said, Chair Khan’s focus appears to be more specific: generative AI. Examining this slice of the “AI market,” there are few signs of big tech entrenchment or flagging competition. OpenAI, who was positioned as the market leader with its release of ChatGPT, is not one of the Big Five tech firms. In fact, OpenAI was only organized as a for-profit in 2019 and today boast a skeleton crew of just 375 employees. Compare this to Google, a significant rival in the chatbot space, who has fallen behind despite a payroll of roughly 160,000 employees and decades of experience. Similar trends exist throughout the broader market where hundreds of smaller, less connected firms are successfully challenging Silicon Valley behemoths. Image generation upstart MidJourney for instance, has a staff of just ten people, and yet they lead the industry with unrivaled technology. One might think Meta, with vast reserves of Instagram photos and a traditional lead in image recognition, should lead this category – and yet smaller actors have prevailed.
A recent leaked Google correspondence highlights big tech’s sudden exposure and the competitive state of play. “We have no moat” warned the correspondence and are “not positioned to win this arms race.”
Hardly the words of an entrenched industrial titan.
Looking beyond software, Khan also indicates a secondary interest in tackling concentration and entrenchment in cloud computing, the industry who’s hardware runs and trains most AI systems. Compared to AI software, cloud computing features a somewhat consolidated market, yet one that is clearly multipolar and thriving.
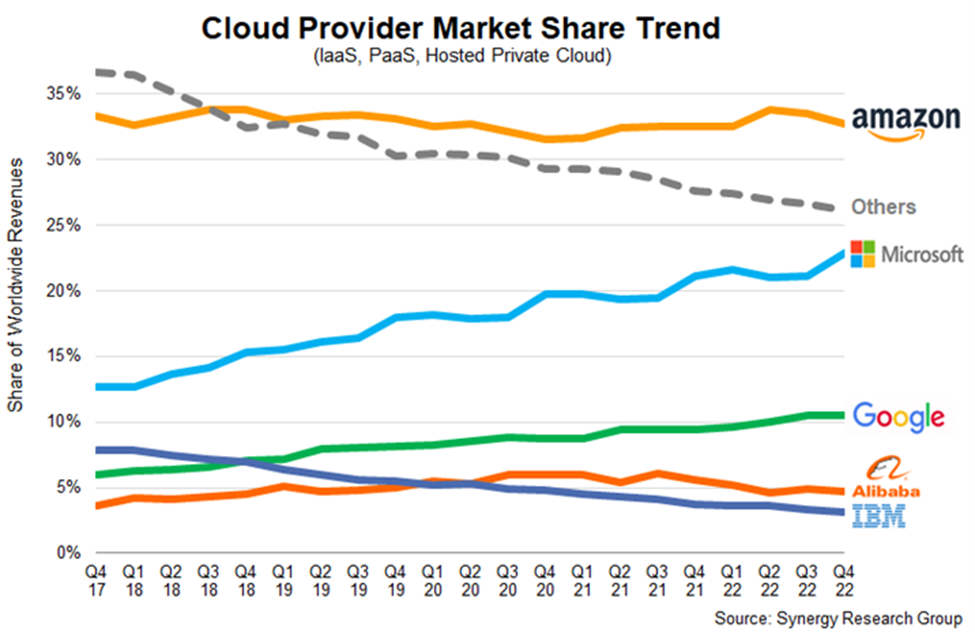
According to Synergy Research, the cloud computing market features 5 major players – mostly the usual suspects. What is notable, however, is that more than a quarter of the market is controlled by a litany of smaller “others.” While the share of these smaller actors is certainly declining, as it stands – big tech cloud computing hegemony is hardly complete. With such diversity, the market gatekeeping Khan warns of would be difficult.
Yet again there is no clear sign of consolidation or entrenchment.
Naturally, none of this is to say that future consolidation is impossible or even unlikely. The point is that it doesn’t exist today. Lina Khan’s messaging is worrying, as it targets problems that don’t exist. At this juncture any market structure regulation would simply act to needlessly pick winners without any clear regulatory upsides.
Here, my recommendation is simple: proceed with caution. The FTC is telegraphing issues that don’t exist and should wait to act until clear evidence of either monopolization or harm to consumer welfare emerges.
Barriers to Entry
Chair Khan’s next outlined priority is to tackle potentially high barriers to entry. For those well acquainted with AI policy, this point is not surprising. When the machine learning revolution kicked off in 2012, barriers to entry were high. Big data itself had only recently hit the mainstream and those who led the revolution were the data rich big tech companies. Likewise, few could rival the server farms of Google, Facebook, or Amazon. This history birthed a now crystalized narrative that AI might be a competition-prohibitive technology because new entrants simply cannot meet data and compute resource demands. Since 2012, however, the tech has evolved and this narrative has mostly crumbled.
While the biggest current barrier is data, this barrier is rapidly shrinking. In recent years so-called foundation models have eased the data resource burden. As ‘foundation’ suggests, these models as a development starting point. On their own, they are capable - yet generic and aimless. When paired with a small, targeted dataset, however, they can be transformed into highly effective products. Many foundation models such as stable Diffusion, have been made free and open source. The result has been a explosion of AI startups harnessing this free real estate to build.
Data barriers have been lowered further by a recent rise of large, open source AI data sets. For instance, Together, an AI startup, recently release RedPajama – an AI toolbox complete with a curated data set of 1.2 trillion data points. With easy access to such extensive resources, anyone can now build. Naturally, additional data beyond free to use sets might still mean the difference between the state of the art and also-rans, but free tools still act to lower the entry gate.
Chair Khan’s second targeted barrier to entry is the high cost of compute. Traditionally, both buying and running AI chips has been exceedingly costly. In 2015, just three years after the machine learning revolution took off, the cost to train a GPT sized model was a staggering $875 million dollars. With such a lofty price tag, it’s understandable why barrier to entry concerns have taken root in the FTC and elsewhere.
As was the case with data, however, this once sky-high barrier has rapidly fallen. A recent report found that the cost of training AI models has dropped roughly 60% per year. What cost $875 million in 2015, cost just $4.5 million in 2020.
Three years later, prices have plummeted further. Foundation models, again, have acted to democratize development. Through a method called transfer learning, developers can essentially re-use the computation that built these models to train new AI products on the cheap. Stanford University researchers demonstrated the cost benefits of transfer learning when they released Alpaca, a chatbot with similar performance to GPT-3.5. The price tag: just $600 dollars.
These reports are more than just anecdotal. In April, the competitive effect of these plummeting prices were confirmed in a blockbuster Center for Security and Emerging Technologies (CSET) report, which concluded that today “AI researchers are not primarily or exclusively constrained by compute.” Once a towering walls, compute costs have eroded to mere speed bumps.
To the credit of Chair Khan, however, some barriers do remain. Training AI systems still costs money, and running them costs even more (though that also is falling). Further, cost declines are uneven. Recall that AI is not a monolith and while generative AI system costs are falling, their market dynamics are not universal. While CSET found that compute isn’t generally a bottleneck, they also found compute demands varied by application. For instance, barriers to entry in computer vision are far higher than in AI-assisted algorithm analysis.
Still, any evidence-based cause for concern is lacking and the industry is more dynamic than ever.
__________________________
I again find it troubling that the FTC is targeting challenges that don’t seem to exist. To these ends, my recommendations for the FTC are twofold:
1. The FTC should take care to update its priors. In rapid fire, problems are being solved and new challenges are emerging. This speed of change demands situational awareness and regulators much continually refresh their understanding of the tech and markets. An FTC burdened by crystalized narratives and outdated priors is destined to misfire, allocating scarce resources to non-issues at the expense of real problems.
2. The FTC should invest in academic outreach. Lina Khan’s op-ed cited compute resource challenges despite CSET’s well-publicized report debunking her cited concerns. CSET is prominent, and the FTC should have been aware of this recent data. Yet, they were not. This speaks to the natural information asymmetries and blind spots of regulatory agencies. Working with independent researchers can help fill these gaps and give the agency a better understanding of the boundless change, complexity, and on-the-ground reality driving the AI ecosystem.
Untrodden Ground and Coming Action
While Chair Khan touches on many other topics, notably fraud prevention and anti-discrimination, for the sake of brevity I’ll leave those topics for another day. At this juncture, we cannot say exactly what actions, rules, or regulations the FTC or other agencies pushing into this space might reveal. Only with time and text can we say if the overall effort will be net beneficial or net harmful.
What we can say, however, is that some form of action is coming. Further, all signs suggest the FTC regulation won’t give AI a light touch.