
Intelligence Convergence: CAPTCHA and the Future of Internet Bot Detection
Considering AI's implications for website accessibility, traffic, and speed.



In the not-so-distant future, an important convergence will occur: the smartest AI agent, navigating the web at the behest of some programmer, will achieve the appearance and capabilities of the simplest human on the internet.
This AI agent’s initial, then subsequent brushes with human-level intelligence will present a fundamental challenge to anti-bot technologies, which are critical to maintain the security of the web. This convergence will force engineers to rethink the purpose of CAPTCHA-like user experiences, lest AI agents run rampant and humans find themselves locked out of their favorite sites.
Anti-botting is an important layer of the internet, and a massive industry exists to help web developers answer the same question: Is the person trying to access my site a human or a bot? In this case, a bot is a computer program that executes code intended to mimic the appearance and capabilities of a human: look there, click here, “don’t mind me; I’m human!”
There are a few important reasons a site would want to use this detection.
Bots can be used maliciously: a website may experience a period of rapid, inflated traffic, most commonly via a Denial of Service (DoS) attack, that overwhelms site resources others may wish to consume. In some cases, DoS attacks can bring down the site altogether, preventing anyone from using the service. This could be accomplished with a well coordinated community of humans. But why subject yourself to this headache when the same could be accomplished with a simple computer program that acts as thousands of humans, in the form of bots. If bots can be used to cheaply and scalably diminish the performance of a website, provisions for detecting and rejecting bots are clearly needed.
Less obviously, bots can be used to access website data and functionality that the website owner may dislike or explicitly ban. Often, websites have valuable data (flight prices, contact information, business leads) that someone wants to scrape and collect with the help of a bot. For example, Kayak wants to have up-to-date flight information from all major airlines, so they may decide to use bots to collect this flight information to keep on their site. But the site may want to protect this data. Or at the very least, prevent bots from accessing it. Unlike a DoS attack, which is a cybercrime, this use case for bots exists in a legal gray area, making it incredibly popular on the web today.
Bots can also be used in a completely benevolent manner that is still troublesome for a website. I may want to run a bot that orders my exact Domino’s order whenever I’m craving pizza. And this bot may successfully enter the correct information, place the order, and use the Domino’s site the exact way they intend a human to use it. Even still, they may not be happy with my Pizza Bot on their site—maybe because they want to show you their latest, cheesiest crust (which the bot takes no heed of)—hence anti-botting.
While some anti-botting techniques evaluate your “robot potential” in the background, a popular technique is presenting you with a test to solve. The idea is that if you ask an agent accessing a site—in the liminal space where human v. bot is not known—to complete a task only a human can complete, only humans will complete it!
We’ve all experienced these anti-botting protections during our time on the web. You are guaranteed to be familiar with the “Completely Automated Public Turing test to tell Computers and Humans Apart”, or CAPTCHA, an anti-botting technique having existed since the late 90s. Given a set of blurry characters and numbers, or a set of images, a human must identify what they are looking at before they can continue using the service. If the human cannot identify the blurry, malformed letters (the spoken description of these blurry, malformed letters in the accessibility case), or the low-res images of fire hydrants, they may not be a human after all.
Before 2021 (i.e. the beginning of the recent AI wave), CAPTCHAs were not easily broken by machines. Previously, classifying an image as having certain characters or containing certain subjects was a resource-intensive and technical undertaking. Where technology failed to defeat technology, paid services flourished that allowed bots to enlist the help of a human compatriot to solve a CAPTCHA (manual CAPTCHA solving), before proceeding with its non-human work.
Then, AI started to rapidly advance. Optical character recognition (OCR) and vision models are now advanced and cheap enough that alphanumeric strings or pictures of fire hydrants can be detected at ease, allowing bots to walk their way into websites by demonstrating this level of human intelligence. Seemingly overnight, this layer of protection was cracked, making it difficult for site owners looking to protect against automated traffic.
But not all hope is lost. CAPTCHA methods have evolved in lockstep, and in the process, become more difficult for humans and bots alike.
One method is the slider CAPTCHA, where you are tasked with dragging a puzzle piece into place on an image. Unlike previous methods, this test evaluates whether you can complete the precise task in a human-like way.

Another recent method you may have encountered on TikTok is the twist slider method, where you must drag a slider to “twist” and align two disjoint pieces of an image to resolve the original photo.

Both CAPTCHAs go beyond simply testing whether a user can identify an image/text by forcing the user to show their work for their answer. If a user takes 60 seconds to drag the puzzle piece, slowly inching the slider to the right a few pixels at a time, it’s likely this is the behavior of a bot. This puzzle plays on the latency weakness of models (processing an image takes time) to keep bots from entering sites.
Other next-generation CAPTCHAs expose other weaknesses of AI models, such as counting the number of objects in an image or identifying the spatial position of objects in an image, such as their direction or position relative to other objects.
Below are three examples of CAPTCHAs in this vein. The first puzzle asks the user to match the animal in the left and right image. The second puzzle asks the user to position the animal (notice that the animal is somewhat abstract) to face the direction the fingers are pointed. The third puzzle asks the user to select the right image that matches the description on the left, which itself abstractly represents “1 heart”.

Perhaps you are wondering, why am I being forced to look through a bunch of CAPTCHAs? Here’s the point: Even as puzzles get more complicated, they are still within the realm of possibility for a human to solve in a timely manner while preventing many bots from accessing sites. But we’re working in the wrong direction.
There are core user experience questions regarding the adoption of increasingly difficult, time-consuming CAPTCHAs as AI capabilities become more advanced. Some that immediately come to mind are:
Does a lengthy, frustrating puzzle lead human users to abandon a site? Thus, rendering some services difficult to use?
If so, is the false positive low enough to justify the real bots successfully intercepted?
Have humans become aware of increasingly difficult CAPTCHAs and has it changed their site usage patterns?
Are there ADA accessibility standards for solving CAPTCHAs that will be more difficult to maintain as puzzles become more complex?
Another consideration: the road to bot-use on the internet is lined with web standards built for accessibility purposes (i.e. screen readers).
Today, CAPTCHA is still an effective tool for filtering out bots while minimizing the number of users inconvenienced by this filter. As far as we know, there hasn’t been a significant internet usage impact from CAPTCHAs becoming marginally harder to complete.
But our attitude changed recently after an experience with OpenAI’s Developer Portal. Prior to a week ago, I hadn’t encountered a CAPTCHA logging into OpenAI. Imagine my surprise when I experienced an absolute beast of a puzzle I’d never seen before.
At first, it was straightforward enough. Given a grid of seats, with rows and columns uniquely labeled with an alphanumeric character or symbol, move the person around from seat-to-seat, using left and right arrows, until they are placed in the correct seat.

My version of the CAPTCHA used numbers and letters to denote rows, not symbols. Interestingly enough, this screenshot comes from a one-year-old YouTube video.
For the first time in my life, I spent a non-trivial amount of time solving the CAPTCHA (~1 minute). And it was genuinely a pain in the ass. There was a moment before I completed it where I was wondering if I would be able to solve it on the first try. Would it take multiple tries? Would I ever be able to access the developer portal again?
And then once more a week later, I watched a peer log into OpenAI and face the same thing. This time, he encountered the third type of puzzle discussed previously: read the directions on the top and in the left image and use the arrows to match the right image. In this case, counting the total number displayed on the dice, using dice pips and dice with actual numbers.
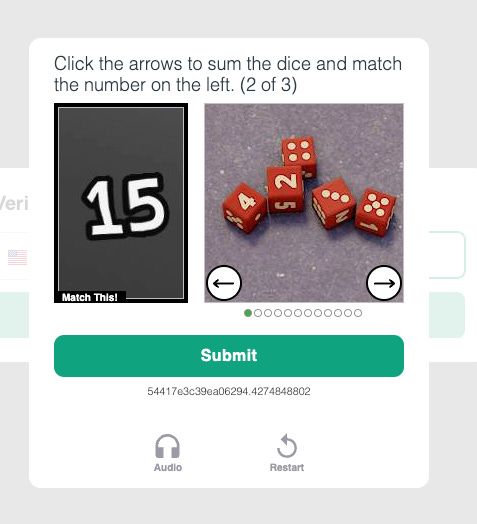
Immediately, these buffed puzzles reminded me of François Chollet’s Abstract Reasoning Corpus (ARC), or ARC Prize challenge, a benchmark for measuring the general reasoning and problem-solving capabilities of AI systems. This benchmark, which uses brain teasers purportedly solvable by young children (“it’s easy for humans; not for AI”), has been unbeatable since its introduction in 2019.
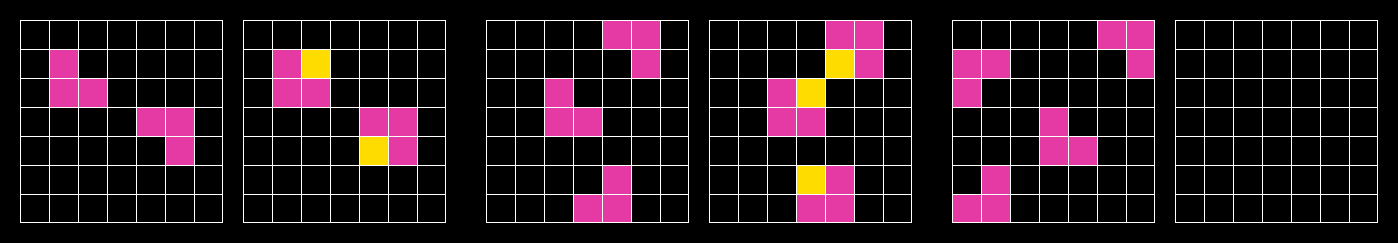
The catch is that these puzzles are actually not trivial to solve, often taking some reasoning before completing. There was at least one I saw that I couldn’t figure out until someone pointed out the solution. This has led multiple non-young-children commentators to point out that the bar for AI is increasingly high, in a way that may begin to alienate busy humans who are focused on, you know, using the website they’re attempting to access for whatever problem they’re working on.
It’s worth noting that it took my peer nine CAPTCHAs and five minutes to successfully authenticate into OpenAI. In terms of user experience, that is a measurable hit to usability. It’s also worth noting that OpenAI’s publicly available models are capable of solving this CAPTCHA in seconds (which hasn’t always been true).

It is clear that the difficulty of these puzzles are reaching an inflection point where site usability, defined as the average web user’s ability to solve the puzzle in a timely manner (if at all), is deteriorating as sites are forced to detect bots in more intelligent ways. I’ve never felt functionally isolated from using a site because of a difficult puzzle. But now I have, twice, in the last week.
Following the path of increasingly sophisticated AI and the constancy of human nature, you have a convergence that forces sites to make a trade-off. When the worst human CAPTCHA solvers become undifferentiated from the best AI CAPTCHA solvers, humans begin to be rejected at the gate in more frequent numbers. While bots can Trojan Horse their way into sites, completely undetected. For an anti-bot developer, the naive trade-off is to make the CAPTCHA more difficult and alienate users or keep the CAPTCHA solvable by the simplest human and open the floodgates for bots to access sites with increasingly high success rates.
At some level, an arms race ensues, and it isn’t clear to us what the equilibrium is.
If human intelligence is different from artificial intelligence in some essential way, maybe we can sidestep the arms race altogether. For example, on many standardized exams, children are asked to identify what pair is analogous to another pair, e.g., “kitten is to cat” as “[what] is to dog,” with the obvious answer being “puppy.” The analogy is obvious to us because we don’t think of kitten as the word “kitten,” we use the word “kitten” to denote that which is a baby, furry feline that has four legs, two pointy ears, likes tuna, and has a tongue that feels like sandpaper. We think conceptually; AI thinks correlatively, i.e., it does not think per se but relates terms, numbers, &c. to others.
This is the intuition behind the ARC Prize, whose visual analogies are effectively unbeatable by AI despite its parallel advancements. It’s worth noting that a Large Language Model (LLM) like GPT-4 can complete written analogies like “kitten is to cat”, but there was a point in which it could not, therefore such a CAPTCHA would be safe from botting. Is this evidence of machine intelligence thinking conceptually? Or seeing enough data to learn a correlative representation of analogy? A topic for another time.
Ultimately, this essential distinction may be meaningless for CAPTCHA design if conceiving (what humans do) and relating (what machine learning does) are functionally identical. Only time will tell.