


Early Thoughts on GPT-4's Policy Implications
2023 is going to be an interesting year


My original plan for this newsletter was to ease into the subject. Then came GPT-4. Digital Spirits will not make a habit of discussing just one company or specific systems; policy should generally treat firms agnostically. That said, the significance of GPT-4 is worth dedicated analysis.
Based on many benchmarks, this system is state-of-the-art and looks likely to change the AI game. That said, after just 48 hours, it’s hard to predict whether it will change the AI Policy game. As the dust around this release has yet to settle, many of these points and observations are very much subject to change and I intend to build on them and flesh them out as we learn more. Narratives tend to crystalize, however, and it’s important to ground the conversation early.
What Is GPT-4?
GPT-4, or Generative Pre-trained Transformer 4, is an advanced AI language model that was released Tuesday by OpenAI. This system builds upon the success of its predecessor, GPT-3 the core technology behind the perhaps familiar Chat-GPT. Both these systems are examples of what are known as Large Language Models (LLMs); a layman can think of them as detailed and powerful chatbots. The power of LLMs is rooted in their diversity. These systems can provide research assistance, write emails, craft poems, code, suggest recipes, annotate images, and many other powerful applications. They are AI multitools.
To create GPT-4, OpenAI trained the system on massive amounts of (largely) text data, which allows it to understand and generate human-like responses to user queries. The result is impressive accuracy, grammatical correctness, and context-awareness.
What makes GPT-4 special?
The original Chat-GPT made a splash as the first LLM system that both seemed to work and was available for public use. What makes GPT-4 special, isn’t novelty but refinement. To illustrate, here are a few brief examples of its enhanced abilities:
1. GPT-4 not only passed the Bar exam but did so in the top 10% of test takers. GPT-3 meanwhile passed in the bottom 10%.
2. GPT-3 could only handle text, while GPT-4 can analyze what is called multimodal input; that is, it can analyze prompts that combine both images and text. While this may sound simple, this task is exceedingly complex.
3. Like its predecessor, GPT-4 can transform descriptions of code into real, functioning software. When solving Leetcode’s programing challenges, its average coding success rate is roughly 2x better that GPT-3’s. When measured against OpenAI’s HumanEval Python coding benchmark, its general coding abilities improved roughly 20%.
4. Other benchmarks suggest improvements in “common sense” and “reasoning.” While these terms are nebulous and difficult to define, my own impression after a few hours of testing confirms this improvement.
5. When summarizing research, GPT-4 now cites sources. My test of its source accuracy suggests that in many cases, the information cited is indeed correct.
Existing Limitations
These highlights demonstrate GPT-4’s substantial improvement over the previous state of the art. AI is advancing fast. Before diving into the policy implications, however, it is important to note a few caveats to this success:
This system is by no means perfect. In many ways, its failures repeat those of GPT-3, though to a much lesser extent. This is a good AI system, and perhaps a good enough system for many applications. Still, there is plenty of room to improve.
While the noted benchmarks that measure LLM success offer a useful method for analyzing improvement, AI benchmarks are themselves a new “science.” These validation points are inherently limited and fail to assess the full range of qualities most would expect from systems of this type. A perfect Bar exam score doesn’t account for all the qualities that make a good lawyer. Likewise, these benchmarks cannot account for all the qualities expected of a useful LLM.
Early Policy Implications
With an understanding of how GPT-4 improves the AI state of the art, lets consider its implications for AI policy. What can we take away from this innovation and how should we approach AI policy in the near term?
1. Don’t Telegraph the Future
GPT-4 is hours old at this point and little can be said about its impact. What we can confidently say is that this will catalyze increased hype and AI competition. Any predictions beyond that, are largely telegraphed. Recall that in the early days of the internet, the system was first treated as a military communications platform and later a limited academic research tool. Few 1970s planners would have predicted the forceful social internet we have today. The internet as we know it is the result of unpredictable, decentralized human effort, playful use of protocols, and unexpected creativity. GPT_4 may have a similar destiny. It cannot be forecasted how users will twist and creatively apply GPT-4’s flexible technology. What we think the tech might be used for today might be totally different 20 years from now. As Deidre McClosky says, “Innovations are unpredictable. That’s why they are innovations.” Policy plans made today should not assume any specific transformative effects.
We also shouldn’t assume wide impact or adoption. GPT-4’s limitations may be bigger obstacles than we recognize. This could create a potential future where it is only used in certain niche applications. While GPT-4’s future certainly looks bright, if LLMs cannot provide consistent value over time, no one will use them.
Finally, it is important to avoid crafting policy around assumed harms. Again, this tech is hours old. We don’t know if GPT-4 will eliminate jobs. We cannot say if it will create novel cyber risk. Nor can we assert that it will meaningfully increase disinformation. Yes, some of these forecasts are absolutely worth taking seriously. To ignore potential risk would be irresponsible. Even so, policymakers should recognize that most existing AI risk reporting makes dramatic assumptions, is lacking in real world context, and can be difficult to divorce from excessive AI hype. Any policy treating these predictions as fact are a recipe for failure. Good policy should seek to solve problems substantiated by clear evidence. Today, most evidence is lacking.
2. Improvement is Possible
It turns out, problems can be solved. After the November release of Chat-GPT, there was widespread concern over its political biases, inaccuracies and mathematical failures. On all these points, GPT-4 improves. To mitigate bias, users can now deploy the new ‘system’ feature, to better tailor output to a specific context or viewpoint. Even when this feature is not in use, anecdotal evidence suggests the system takes a more nuanced, balanced approach to controversial issues and research questions. As for accuracy and mathematical skill, when tested on select categories, including math, GPT-4 shows up to a 20% improvement.
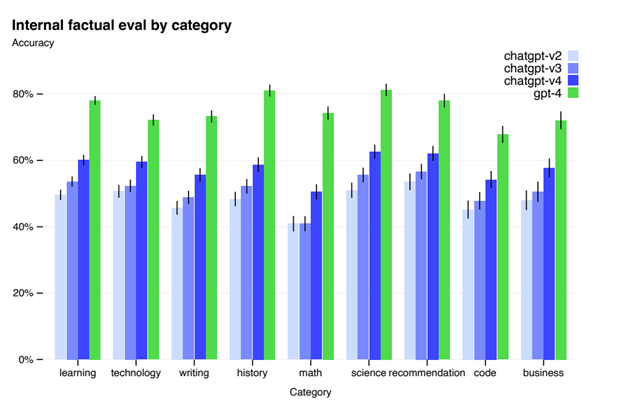
Image Source: GPT-4 Technical Report, OpenAI, https://arxiv.org/abs/2303.08774
This simple realization matters profoundly. Not only did GPT-4 show progress just three months after Chat-GPT’s release, but it showed progress on many of the biggest publicized AI challenges. GPT-4 appears to be less racist, less sexist, more balanced and more accurate.
The point is that we have yet to see a persistent failure in need of correction. Markets are indeed adjusting.
Regulators should allow both the flexibility and time needed for this innovation to continue. Thus far, the track record supports a relatively well functioning incentive structure that has encouraged productive competition. Note that we may eventually discover intractable problems that require regulation. Today, however, markets largely seem to be working and we should forgo the uncertainties of most dramatic regulation until a problem clearly needs solving.
3. Avoid Outdated Narratives
What can be confirmed, is narrative failure. Ideas about AI weaknesses tend to be based on outdated snapshot perspectives rather than a nuanced sense of improvement over time. We still regularly hear about facial recognition’s racial bias problems, a narrative largely rooted in shocking data from a 2012 study when the tech was still young. By 2018, the National Institute of Standards and Technology found that state-of-the-art facial recognition had reached error rates below 0.2%. The recorded errors in large part were attributed to facial injuries and aging, not race. Five years on, this error rate has probably shrunk even more.
Just as narratives about facial recognition have failed to update based on new evidence, we are likely to continue to hear about the original Chat-GPT’s weaknesses well after its obsolescence. Policymakers should continually consult data and ensure their understanding of these challenges is up to date with these and other improvements.
4. Open Criticism Matters
One of the most important institutional ingredients contributing to GPT-4’s improvement has been free speech and open critique. It has now been confirmed that the AI powered edition of Bing released in February was secretly running on top of GPT-4. While the February edition of Bing exhibited racism, outbursts, and at times drifted into bizarre character role playing, GPT-4 is relatively staid. Given these differences, it seems likely the Bing deployment acted as a ‘testing’ phase for GPT-4. Before the model’s official release, Journalists were free to tear Bing apart and openly criticize its failures in the public eye. While perhaps embarrassing for Microsoft, this process was constructive. Resulting from the intense public criticism is a system that is harder to ‘jailbreak’ or goad into improper behavior, less outrageous, and perhaps more useful overall. Criticism led to accountability – accountability to innovation – and innovation to a better product. Perhaps it really was a good Bing.
Not only was this process effective, but it was also responsible. Bing was never dangerous, despite hyped-up claims, and the audience with access was highly selective and limited. Never was GPT-4 carelessly flung at those without an understanding of its limits. This “AI Sandbox” of sorts worked perfectly, isolating its effects to in-the-know experts and journalists to minimize harm and maximize accountability.
For policymakers, this perhaps should serve as a model of responsible testing. Given their complexity, these systems will be difficult to fully test in a laboratory setting. Only when confronted by the unpredictable creativity of wider human input, and resulting critique, can the range of their failures be discovered. Policy should continue to service this model and any restrictions on machine generations or journalistic critique that might disincentive this form of testing should be avoided.
5. Don’t let Alignment Discourse Distract.
In their introductory blog post, OpenAI has proudly claimed they “spent 6 months iteratively aligning GPT-4” (emphasis added). “Alignment” is a term of art that refers to the goal of aligning AI behavior with human desired outcomes. Definitionally simple, yet evocatively more complex. Alignment discourse tends to drift into often-rash assumptions about existential risk, engineering self-aggrandizement, and even machine sentience. The term is grandiose and reflects a certain egotism that pervades the field.
For OpenAI, what did “Alignment” mean in a practical sense? It’s just testing. Just as a bug in Microsoft Excel might twist a formula, creating an incorrect graph; a bug in GPT-4 might cause it to respond to a prompt with inaccurate information. Like in Excel, when such a bug is discovered in GPT-4, it needs to be resolved. Language like ‘alignment’ seeks to hide the fact that these examples are not dramatically different.
Yes, GPT-4’s testing and bug swatting is realistically more difficult than Excel’s. Further, the technology’s potential requires AI engineering to have a keen sense of philosophy, policy, and social impact. AI is a goal after all, and that goal should always keep in mind the progress we want to see as a society. That said, the use of such language, and the increasing cache of its over-caffeinated advocates, creates the risk of painting the engineering and testing process as something of a moral or even spiritual crusade. While LLM engineering may vary in requirements and process, at the end of the day, testing is still testing. Policymakers should avoid this type of hype, the alignment-associated mysticism that has seeped into AI thought. Policy should aim to reflect real challenges and the boring everyday reality of engineering. These systems are products, not phenomenon.
More to Come
As mentioned, these thoughts are just a few early takeaways. Specifically missing are the potential foreign policy implications. I will likely address those in a follow-up in the coming days. Please note that these takeaways are subject to change as we may yet see harm, dramatic potential, or dramatic failure. As GPT-4 is put into use and the world reacts, we will develop a better sense of its significance.
Its going to be an interesting year.